## 内容大纲### 1. 引言- 比特币的兴起与普及- 钱包软件的重要性### 2. 什么是比特币钱包?- 比特币钱包的定义- 钱包类...
在当今数字货币迅猛发展的环境中,比特币作为最具知名度的虚拟货币,吸引了大量投资者的关注。为了更好地监控市场动态,许多人希望能够获取比特币钱包的信息,了解其交易状况和账户余额。在这一需求背景下,网络爬虫作为一种自动获取信息的有效工具,显示出其重要性。
本文旨在全面解析如何利用Python这一编程语言,通过网络爬虫技术来抓取比特币钱包相关的信息。我们将涵盖基本知识、技术细节以及实际应用案例,帮助读者掌握这项技术。
### 二、比特币钱包的基本信息 #### 什么是比特币钱包比特币钱包是一个用于存储和管理比特币的数字工具。与传统的钱包不同,它能够在电子设备上存储比特币的新型货币。每个比特币钱包都有一个唯一的地址,用户可以通过这个地址进行发送和接收比特币。
#### 钱包的类型比特币钱包通常可以分为几种类型,包括:硬件钱包、软件钱包、纸钱包和在线钱包。硬件钱包通常被认为是最安全的存储方式,但使用功能较为复杂;软件钱包便于使用,适合频繁交易的人士;纸钱包则是将钱包信息打印出来,虽然安全性高,但不便于使用;而在线钱包则通过互联网提供服务,但相对安全性较低。
#### 钱包的工作原理比特币钱包通过实现密钥管理来工作。用户拥有一对公共和私有密钥,其中公共密钥可以公开与他人分享,用于接收比特币,私有密钥则需要严格保密,用于交易授权。钱包的功能不仅是储存余额,还包括发送和接收比特币、查看交易历史等。
### 三、Python爬虫基础 #### 什么是网络爬虫网络爬虫是自动访问互联网并抓取信息的程序。无论是搜索引擎,还是数据分析平台,都需要爬虫技术来获取互联网中的海量信息。
#### Python中的爬虫库 - **requests库**:用于发送HTTP请求,获取网页内容。 - **BeautifulSoup库**:用于解析网页HTML,提取需要的数据。 - **Scrapy框架**:完善的爬虫框架,支持异步处理,适合大规模爬取。 #### 爬虫的基本流程爬虫的基本流程主要包括:发送请求、获取响应、解析数据和存储数据。首先,程序向目标网站发送请求,获取网页的HTML代码;接着,依靠解析库处理网页内容,提取所需信息;最后,将抓取的数据保存到数据库或者文件中。
### 四、比特币钱包信息源 #### 收集网址与API在进行爬虫之前,首先需要确定数据源。对于比特币钱包的信息,可以通过官方API获取,或者在相关网站中查找地址和交易记录。
#### 数据格式及结构网页中的数据通常以HTML的形式存在,了解基本的HTML标签和结构对于数据提取至关重要。此外,有些API可能返回JSON格式数据,解析方法也有所不同。
#### 反爬机制与应对措施很多网站为了保护自身数据,设置了反爬虫机制,例如请求频率限制、IP封禁等。应对这些措施,可以通过设置请求头、加大请求间隔、使用代理IP等方式。
### 五、实际爬虫案例 #### 环境准备在开始编码之前,需要安装相关的Python库。在命令行中运行“pip install requests beautifulsoup4”可以完成安装。确保Python环境正常工作且对网络连接可用也至关重要。
#### 数据抓取示例代码 ```python import requests from bs4 import BeautifulSoup url = 'https://example.com/bitcoin-wallet' response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') # 提取必要信息示例 wallet_info = soup.find_all('div', class_='wallet-data') for info in wallet_info: print(info.text) ``` #### 数据解析与存储获取后,通常需要对数据进行清洗和格式化,以便进行后续分析。可以选择存储到CSV文件或者数据库中。
### 六、数据分析与利用 #### 如何分析爬取的数据爬取到的数据可以用来分析市场趋势、用户行为等。可以使用Python中的pandas库进行数据处理和分析,生成统计报告。
#### 数据可视化数据可视化是将数据以图形方式呈现的重要过程。可以使用Matplotlib或Seaborn库,实现数据的可视化展示。
#### 可能的应用场景针对比特币钱包的数据分析可以应用于投资决策、市场监测、风险评估等多个领域,帮助用户作出更理性的决策。
### 七、常见问题解答 #### 1. 爬虫抓取比特币钱包数据是否合法?合法性问题往往与目标网站的使用条款相关。大部分网站在其条款中会列出关于数据抓取的政策,获取之前最好进行了解。一般而言,如果只针对公开数据,且不违反网站政策,就是合法的。
#### 2. 如何处理反爬虫机制?简单地说,就是通过友好的方式来模拟一个正常用户的行为。要经常进行请求,设置合理的请求间隔,还可以使用代理IP和多线程技术来提高效率。同时,伪装User-Agent也是常见的做法。
#### 3. 如何提高爬虫的效率?可以通过多线程和异步请求来提高爬虫的效率。例如,使用asyncio和aiohttp库来处理网络请求,提高抓取速度。此外,合理设置超时时间和重试机制,也能使爬虫更加稳定可靠。
#### 4. 有没有免费的API可以获取比特币钱包数据?是的,许多网站和服务提供免费的API,比如CoinGecko、Blockchain.info、CryptoCompare等都提供有关比特币钱包和市场数据的API接口,详细查看他们的文档即可。
#### 5. 爬取的数据如何保护隐私?在爬取过程中,确保不抓取敏感数据,如用户的身份信息。对于抓取的内容,存储过程中应采取加密措施,防止数据泄露。
#### 6. 如何保证长时间稳定抓取?为了实现稳定性,建议使用定时任务工具,定期运行爬虫程序。同时,需定期监测爬虫效果和状态,适时调整抓取策略,以应对网页结构和反爬虫机制的变化。
### 八、结论随着数字货币的普及,数据爬虫技术将发挥越来越重要的作用。通过Python的爬虫技术,便能够快速获取比特币钱包相关的信息,助力用户更好地理解市场动态和进行投资决策。希望本文能够为读者提供实际的帮助,以便在这一领域深入探索。




## 内容大纲### 1. 引言- 比特币的兴起与普及- 钱包软件的重要性### 2. 什么是比特币钱包?- 比特币钱包的定义- 钱包类...

### 内容主体大纲1. **引言** - 数字资产的普及 - 钱包的必要性2. **什么是Cloud Token钱包** - Wallet功能介绍 - 支持的加密货...
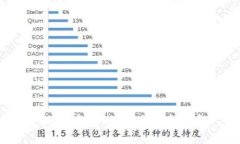
## 内容主体大纲1. **引言** - 以太坊简介 - 挖矿的基本概念 - 钱包的作用与类型2. **以太坊挖矿的工作原理** - 挖矿的流...
## 内容主体大纲1. **引言** - 介绍以太坊和比特币的基本概念。 - 说明跨链资产管理的重要性和发展背景。2. **以太坊...